Each row represents one month of sales (in millions of US dollars).
Time series resampling
Suppose that we need predictions for one year ahead and our model should use the most recent data from the last 20 years. To set up this resampling scheme:
This resampling scheme has 58 splits of the data so that there will be 58 ARIMA models that are fit. To create the models, we use the auto.arima() function from the forecast package. The rsample functions analysis() and assessment() return a data frame, so another step converts the data to a ts object called mod_dat using a function in the timetk package.
library(forecast) # for `auto.arima`library(timetk) # for `tk_ts`library(zoo) # for `as.yearmon`fit_model <-function(x, ...) {# suggested by Matt Dancho: x %>%analysis() %>%# Since the first day changes over resamples, adjust it# based on the first date value in the data frame tk_ts(start = .$date[[1]] %>%as.yearmon(), frequency =12, silent =TRUE) %>%auto.arima(...)}
Save each model in a new column:
roll_rs$arima <-map(roll_rs$splits, fit_model)# For example:roll_rs$arima[[1]]
(There are some warnings produced by these regarding extra columns in the data that can be ignored.)
Model performance
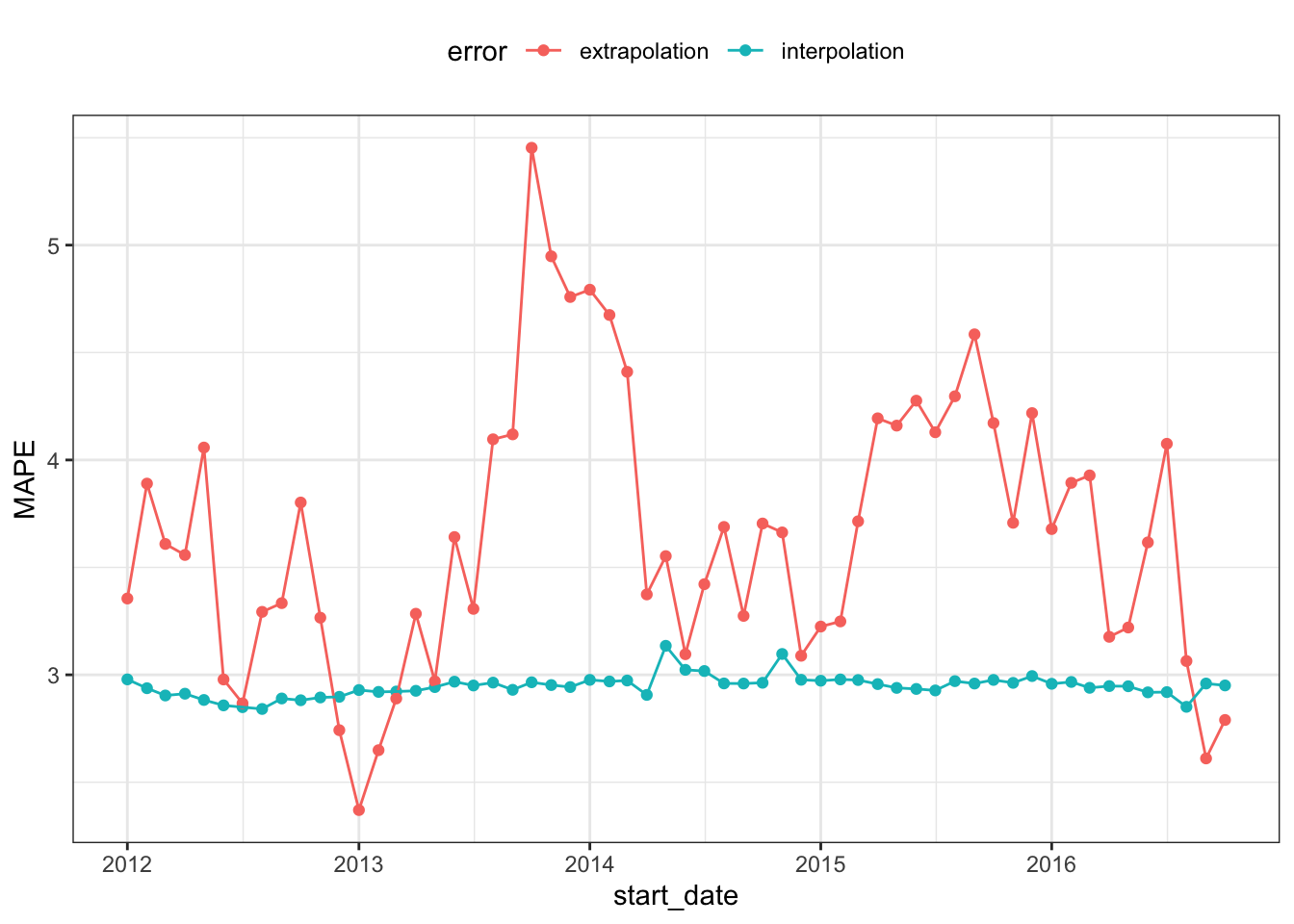
Using the model fits, let’s measure performance in two ways:
Interpolation error will measure how well the model fits to the data that were used to create the model. This is most likely optimistic since no holdout method is used.
Extrapolation or forecast error evaluates the performance of the model on the data from the following year (that were not used in the model fit).
In each case, the mean absolute percent error (MAPE) is the statistic used to characterize the model fits. The interpolation error can be computed from the Arima object. To make things easy, let’s use the sweep package’s sw_glance() function:
It is likely that the interpolation error is an underestimate to some degree, as mentioned above.
It is also worth noting that rolling_origin() can be used over calendar periods, rather than just over a fixed window size. This is especially useful for irregular series where a fixed window size might not make sense because of missing data points, or because of calendar features like different months having a different number of days.
The example below demonstrates this idea by splitting drinks into a nested set of 26 years, and rolling over years rather than months. Note that the end result accomplishes a different task than the original example; in this new case, each slice moves forward an entire year, rather than just one month.
# The idea is to nest by the period to roll over,# which in this case is the year.roll_rs_annual <- drinks %>%mutate(year =as.POSIXlt(date)$year +1900) %>%nest(data =c(date, S4248SM144NCEN)) %>%rolling_origin(initial =20, assess =1, cumulative =FALSE )analysis(roll_rs_annual$splits[[1]])